Understanding Job Titles | SQL/Pandas | Webscraping
Understanding the Data Titles in the Industry
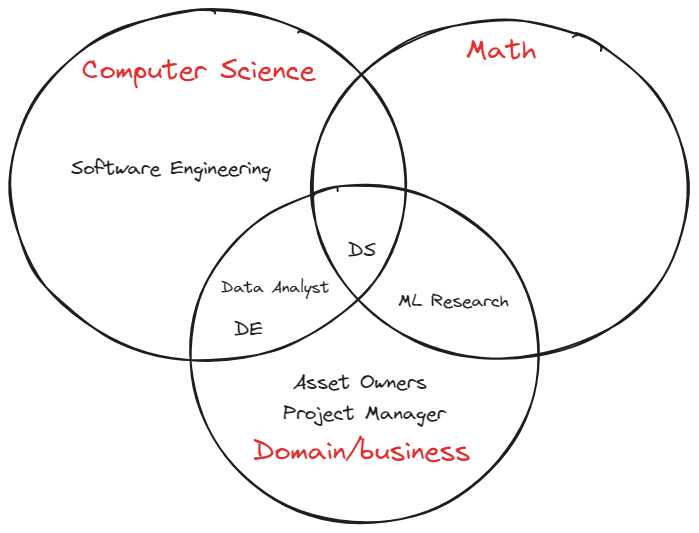
Below are summarized titles and responsibilities typically expected of each role in the data industry.
- Data Analyst
Analyzes data and provides insights to stakeholders.
- Data Scientist
Develops models from existing or new data sources and deploys them. These roles tend to be more research-focused or require a strong engineering background to deploy models into production.
- Data Engineer
Builds and maintains data pipelines, ranging from data sources to data warehouses. Proficiency in SQL is essential for success in this role.
- Machine Learning Engineer
Constructs and maintains machine learning pipelines and understands model deployment processes.
- Data Architect
Designs and builds data systems, including data warehouses, data lakes, and data pipelines. This role is typically very senior and plays a crucial part in guiding the data team.
- Software Engineer
Develops web applications or APIs that enable users to create and interact with data.
Introduction to Sql/ Pandas
In the previous section, we gained a general understanding of various data roles. This section will focus on the roles of the data engineer and data scientist. We will be using SQL and Pandas to learn how to extract and manipulate data from databases.
SQL is a language specifically designed for interacting with databases.
Many organized datasets are stored in databases, which can be either relational or non-relational. In the industry, SQL tables are commonly used.
Given that this course is primarily focused on Python, I will provide a basic translation to bridge the concepts.
- Selecting Data:
SELECT * FROM table_name;
SELECT column1, column2 FROM table_name;
Pro-tip: In job interviews do not just use SELECT * FROM table_name. You are reading the entire table and that is not efficient.
df # Within Jpuyter notebook this will print the entire dataframe
df[['column1', 'column2']]
- Filtering Data:
SELECT * FROM table_name WHERE condition;
SELECT * FROM table_name WHERE condition1 AND/OR condition2;
df[df['column'] condition] # df[df['cat_age'] > 5]
- Sorting Results:
SELECT * FROM table_name ORDER BY column ASC/DESC;
df.sort_values('column', ascending=True/False)
- Joining Tables:
SELECT * FROM table1 INNER JOIN table2 ON table1.column = table2.column;
SELECT * FROM table1 LEFT/RIGHT JOIN table2 ON table1.column = table2.column;
pd.merge(df1, df2, on='column', how='inner')
- Aggregating Data:
SELECT COUNT(column), SUM(column), AVG(column), MAX(column), MIN(column) FROM table_name;
df.agg({'column': ['count', 'sum', 'mean', 'max', 'min']})
- Grouping Results:
SELECT column, COUNT(*) FROM table_name GROUP BY column;
SELECT column, COUNT(*) FROM table_name GROUP BY column HAVING COUNT(*) > N;
df.groupby('column').size()
df.groupby('column').filter(lambda x: len(x) > N)
- Combining Results from Multiple Queries:
SELECT * FROM table1 UNION SELECT * FROM table2;
SELECT * FROM table1 UNION ALL SELECT * FROM table2;
pd.concat([df1, df2]).drop_duplicates()
## Beware of concating multiple dataframes. Its very compute intensive
- Inserting Data:
INSERT INTO table_name (column1, column2) VALUES (value1, value2);
df = df.append({'column1': value1, 'column2': value2}, ignore_index=True)
- Updating Data:
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;
df.loc[df['column'] condition, ['column1', 'column2']] = [value1, value2]
- Deleting Data:
DELETE FROM table_name WHERE condition;
df = df[~(df['column'] condition)]
- Creating Tables:
CREATE TABLE table_name (column1 datatype, column2 datatype, ...);
df = pd.DataFrame(columns=['column1', 'column2'])
- Altering Tables:
ALTER TABLE table_name ADD column_name datatype;
ALTER TABLE table_name DROP COLUMN column_name;
df['new_column'] = pd.Series(dtype='datatype')
df.drop('column_name', axis=1, inplace=True)
- Using Subqueries:
SELECT * FROM table_name WHERE column IN (SELECT column FROM another_table);
df[df['column'].isin(another_df['column'])]
- Limiting Results:
SELECT * FROM table_name LIMIT number;
df.head(number)
- Using Distinct:
SELECT DISTINCT column1, column2 FROM table_name;
df[['column1', 'column2']].drop_duplicates()
# I would prefer the unique method if you need a quick preview
Once your comfortable reading SQL put it into practice! Check out this SQL Game and try to complete the exercises.
Introduction to Webscraping
People web scrape for various reasons. The most common one is to extract data from websites that do not offer an API. APIs dedicated to delivering data are generally more stable and provide data in a consistent format.
Web scraping enables you to extract data from websites, enhancing your existing datasets.
It’s one of the many tools you can use to explore different correlations.
Here is my current project and a fun project that someone else did: covid yankee candle reviews
Python Snippet for Webscraping:
import requests
import pandas as pd
from bs4 import BeautifulSoup
# URL to scrape
url = 'https://www.scrapethissite.com/pages/forms/'
# Send HTTP request
response = requests.get(url)
response.raise_for_status()
# Parse the HTML content
soup = BeautifulSoup(response.content, 'html.parser')
# Find the table
table = soup.find('table')
# Extracting table data
table_data = []
headers = []
# Extract headers
for th in table.find_all('th'):
headers.append(th.text.strip())
# Extract rows
for row in table.find_all('tr')[1:]: # Skipping the header row
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
table_data.append(cols)
# Create DataFrame
df = pd.DataFrame(table_data, columns=headers)
df.head()
# you can also use pandas to read html - pd.read_html(url) I have not tested this so beware..
Tips about webscraping:
- For real-world sites, you will need to use developer tools to find the correct HTML tags.
- Include headers in your request to avoid getting blocked.
- Use a proxy if you are scraping a large amount of data. Respect the website and avoid overloading it with requests.
- Use Selenium if you need to interact with the website, especially when sites use JavaScript to load data.