Whisper audio transcription with diarization
How to Guide
If you have a use case for transcribing audio calls and getting the information pulled out into a json format, this is the guide for you. The model I am using is Whisper, since its open source release from OpenAI - there are faster implementation from its base with flash attention: gitlink
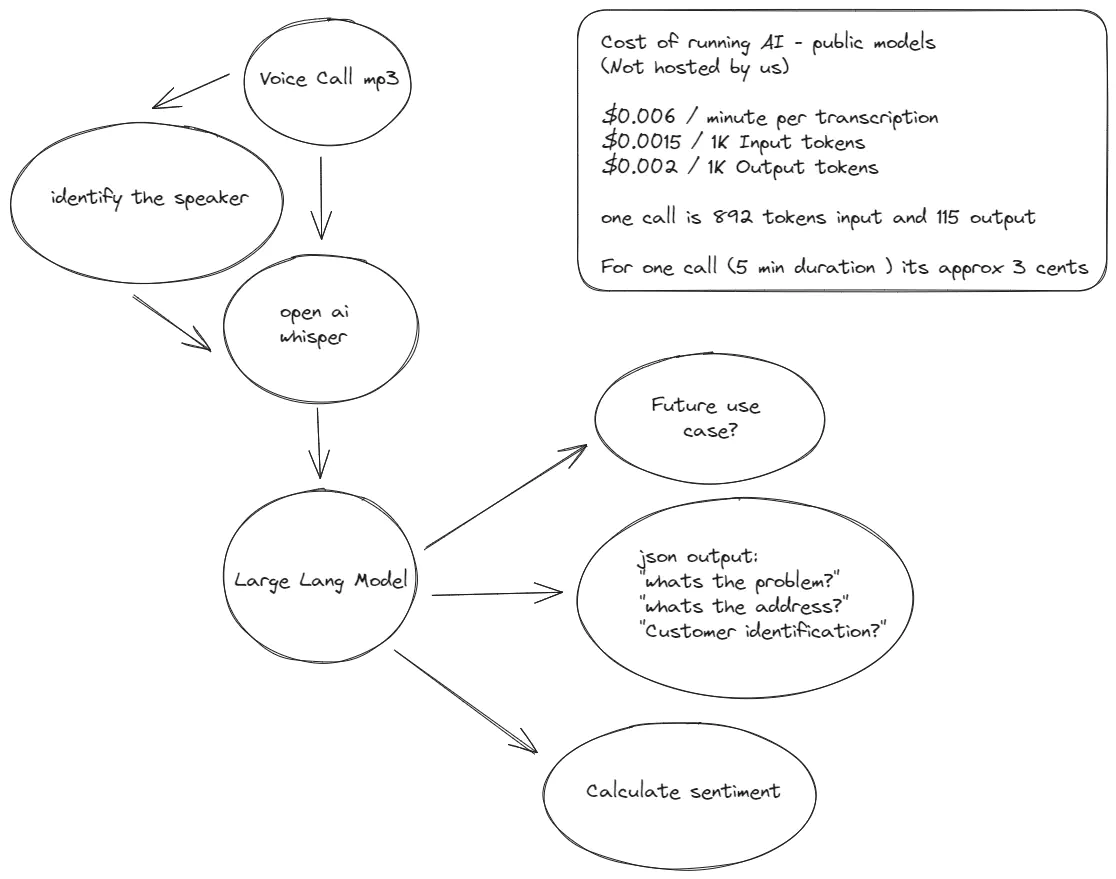
The architecture follows
- Identify Speaker
- Break Audio into chunks
- Transcribe Audio
- Analysis of each speaker
For our example we will be using OpenAI API
Identify speaker
speaker_diarization = Pipeline.from_pretrained("pyannote/speaker-diarization-3.0"
,use_auth_token=HUGGING_TOKEN)
who_speaks_when = speaker_diarization(filepath,
num_speakers=None,
min_speakers=None,
max_speakers=None)
Well how do you break the audio apart??? Sorry bud I am trying to monetize this feature. Do it yourself 😑
Transcribe Audio
Once you get the chunks apart you can do a simple transcription with the following code
import openai
filepath = "audio_file.mp3"
audio_file= open(filepath, "rb")
raw_transcript = openai.Audio.transcribe("whisper-1", audio_file)
Analysis of each speaker
Once you have the transcription of each speaker - finding a specific speaker is a simple search. Customer reps tend to ask “how are you doing?”
Well use the trusty embed for each customer rep line to the transcription to find which speech is the closest to the question.
import fasttext
import fasttext.util
# Download English model
fasttext.util.download_model('en', if_exists='ignore')
ft = fasttext.load_model('cc.en.300.bin')
# Let's assume these are the transcriptions from different speakers obtained from the previous steps
# Common phrases that a customer service rep might say
customer_service_phrases = [
'How can I assist you?',
'How can I help you today?',
'Thank you for calling Customer Support.',
'Is there anything else I can help you with?',
]
# Compute the average embedding of customer service phrases
cs_embedding = sum(ft.get_sentence_vector(phrase) for phrase in customer_service_phrases) / len(customer_service_phrases)
# Compute the similarity between speakers' text and customer service phrases
similarities = {}
for speaker, text in transcriptions.items():
speaker_embedding = ft.get_sentence_vector(text)
similarity = sum(cs_embedding * speaker_embedding) # cosine similarity can also be used
similarities[speaker] = similarity
# Identify the speaker with the highest similarity as the customer service rep
customer_service_rep = max(similarities, key=similarities.get)
print(f"The customer service rep is likely: {customer_service_rep}")
LLM Open Function
Now that you have speaker identification and transcription you can use open functions to pull out critical information
Create a class for the information you want to pull out.
class rubric_judge(BaseModel):
rubric_name: str = Field(..., description="Did you ask for there name/company?")
rubric_contact: str = Field(..., description="Did you ask for there email/phone number?")
rubric_addr: str = Field(..., description="Did you ask for their address?")
class CallInformation(BaseModel):
pickup_name: str = Field(..., description="Give me the full name of the customer")
pickup_street: str = Field(..., description="Give me the street address, zipcode and state")
asset_num:int = Field(..., description='Give me the asset number provided for the machinery')
problem_description: str = Field(...,description="Provide a brief description of the problem that the customer called for")
Utilize the class above for call transcription pullout
def get_completion_from_messages(messages,
model="gpt-3.5-turbo",
temperature=0):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=3000,
functions=[
{
"name": "extract_call_transcription",
"description": "Extract important information from call transcript",
"parameters": CallInformation.schema()
}
],
function_call="auto",
)
print(response)
function_call = response.choices[0].message["function_call"]
arguments = json.loads(function_call["arguments"])
return arguments
By calling the function you can get the message results
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Return n/a if you dont know."})
messages.append({"role": "user", "content": f" I am giving you a call transcript : {raw_transcript}"})
results=get_completion_from_messages(messages)
Your output should be similar to this :
{'pickup_name': 'Chris',
'pickup_street': '144 main street',
'asset_num': 777958,
'problem_description': 'The machine is broken, the pulley system is broken'}
The use case are plenty once you know the problem description - you can classify the problem and route the call to the correct department.