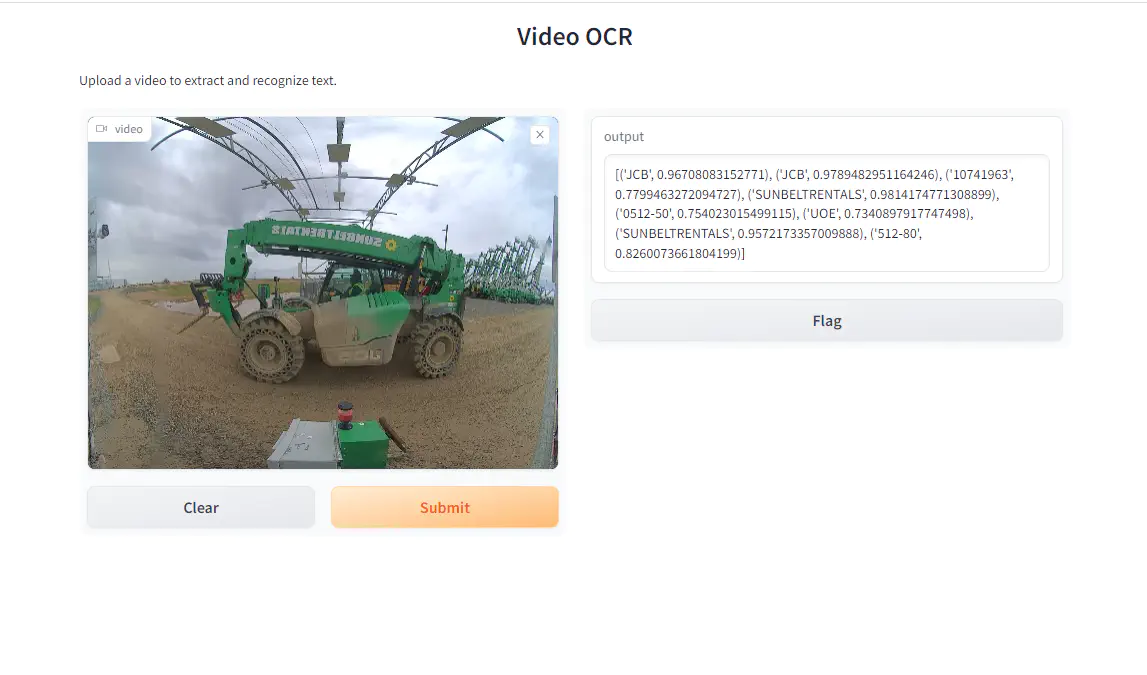
Video OCR for Asset Tag
Video ocr is pretty much image ocr - its just video frames into images.
There is a number of ways to save compute and time: image segmentation or yolo bounding boxes on things you want to focus on.
For this example - we wont be using that its just simple text detection, recognition.
- For text detect we are using easyocr dbnet detection that would break down each image into its corresponding text
Perform some basic image preprocessing to thresholding, gauss blur, and also expanding the picture.


Use paddlepaddle for text recognition: Why have two ocr packages? Easyocr is pretty simple to install and later building determinitic functions to determine if the video is flipped. Paddle has built in algos for different recognition and detection.
Use Gradio as a front end where you can drag and drop videos for results
Code snippets
folders = ['frames', 'text_images', 'processed_images']
for folder in folders:
if not os.path.exists(folder):
os.makedirs(folder)
# Run the existing code
frames_folder = "frames"
output_folder = "text_images"
processed_folder = "processed_images"
bd.save_frames(video, frames_folder)
bd.flip_images(frames_folder)
bd.detect_text(frames_folder, output_folder)
bd.image_preprocessing(output_folder, processed_folder)
text = bd.ocr_text(processed_folder)
#Clean up folders
for folder in folders:
shutil.rmtree(folder)
return text
Once you read into the code, the problems you can spot are IO to read/write frames and also doing OCR on every frame. The question becomes can you develop a YOLO model to detect the asset tag and then perform OCR on that specific area. This would save time on character recognition and also reduce the amount of frames you need to process.
Improvements?
- Add more image preprocessing to make the text more readable
- Incorporate addition ocr recognition packages to improve accuracy
- Dockerfile to package the entire setup for API deployment
- Add YOLO model to detect asset tag and then perform OCR on that specific area