Q/A with Sentence Transformers (RAG)
Context
In the age of LLM every business director is trying to stay hip and learn the new trends of AI. So the many tutorials that exist out there gives pretty much the same thing.
Given a word doc and a question how can my LLM answer the questions?
You can always copy and paste the entire document into the LLM, but you risk the problem of scale.
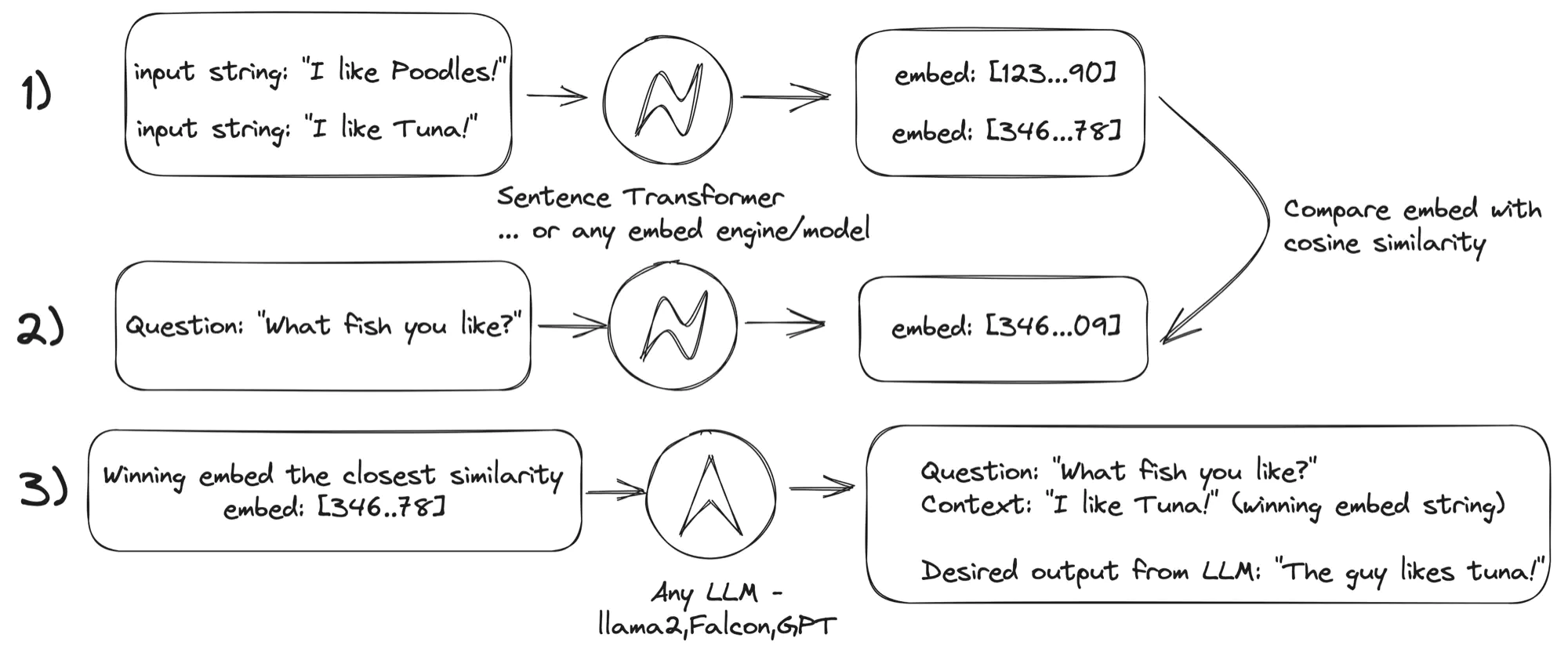
What if you have tens of thousands of documents? Here comes vector embeddings to the rescue.
You can apply a vector embedding (some number that represents the document) to the document and the question. Then you can compare the similarity of the question to the document.
from sentence_transformers import SentenceTransformer
# Initialize the sentence transformer model
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# Define the sentence to embed
sentence = "I like Tuna!"
# Embed the sentence
embedding = model.encode([sentence])
# Print the embedding
print(f"Sentence: {sentence}")
print(f"Embedding: {embedding[0]}")
By retrieving the best similarity score, you can then retrieve the document that best answers the question.
# Initialize the sentence transformer model
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# Define the sentences to compare
sentence1 = "This is the first sample sentence."
sentence2 = "This is the second sample sentence."
# Embed the sentences
embedding1 = model.encode([sentence1])[0]
embedding2 = model.encode([sentence2])[0]
# Compute the cosine similarity between the two embeddings
cosine_similarity = 1 - cosine(embedding1, embedding2)
# Determine the "winning" sentence
if cosine_similarity > 0.8:
winner = "The sentences are very similar."
elif cosine_similarity > 0.5:
winner = "The sentences are somewhat similar."
else:
winner = "The sentences are different."
# Print results
print(f"Sentence 1: {sentence1}")
print(f"Sentence 2: {sentence2}")
print(f"Cosine Similarity: {cosine_similarity}")
print(f"Winner: {winner}")
Feed that back to the LLM. Wala —– You get your answer without wasting calls to your LLM and driving up costs.
# Define the winning sentence and the question you want to ask
winning_sentence = "I like Tuna!"
question = "What kinda fish you like?"
# Combine the context and the question
prompt = f"Context: {winning_sentence}\nQuestion: {question}\nAnswer:"
# Make an API call to generate a response
response = openai.Completion.create(
engine="gpt-3.5-turbo", # Use the appropriate engine ID for GPT-3.5
prompt=prompt,
max_tokens=100 # Limit the response to 100 tokens
)
# Extract and print the generated answer
answer = response.choices[0].text.strip()
print(f"Question: {question}")
print(f"Answer: {answer}")
General improvments
- Figure out chunking texts for longer documents and understand a good breaking point per chunk
- Scaling out vectors means figuring out a vector database: Pinecone, Weivate or Milvus are generally popular. Chroma has plenty of examples in LangChain documentation.